 Apache Spark
Apache Spark Particionado en Apache Spark
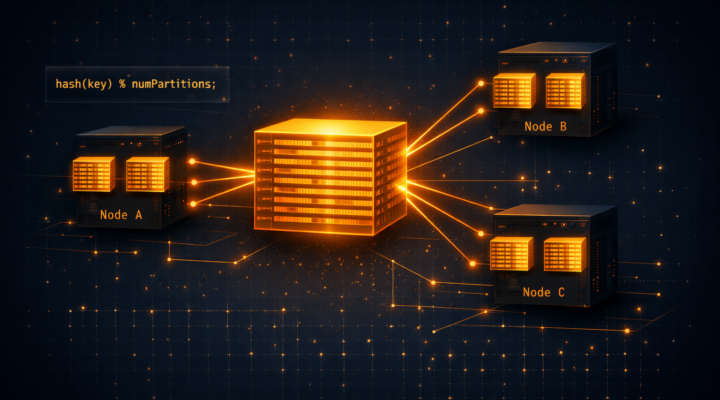
Los RDD operan con datos no como una sola masa de datos, sino que administran y operan los datos en particiones repartidas por todo el…

Senior Data Engineer & Instructor
Big Data · Cloud · Spark · Snowflake · IA
Apache Spark Los RDD operan con datos no como una sola masa de datos, sino que administran y operan los datos en particiones repartidas por todo el…
 Apache Maven
Apache Maven Apache Maven está diseñado para crear compilaciones portátiles que se espera que funcionen en diferentes plataformas y en varios entornos de tiempo de ejecución. Puede…
 Apache Spark
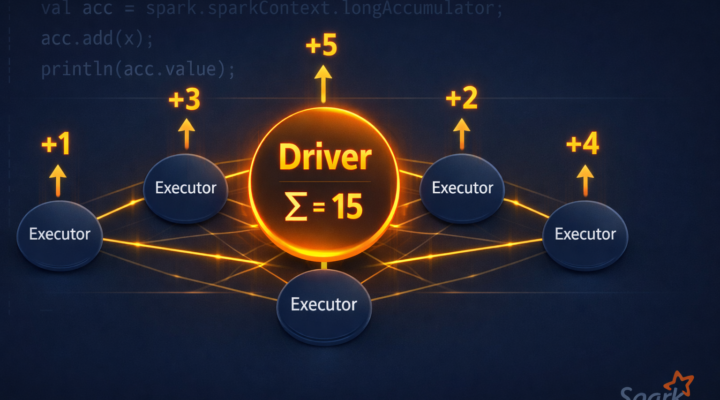
Apache Spark Los acumuladores son variables compartidas entre ejecutores que normalmente se utilizan para agregar contadores a su programa Spark. En un entorno distribuido como Apache Spark,…
 Apache Maven
Apache Maven ¿Qué es un JAR con dependencias? Un requisito típico de los proyectos es agregar la salida junto con sus dependencias, módulos y otros archivos en…
 Apache Spark
Apache Spark Apache Spark es uno de los frameworks de procesamiento de datos más utilizados en el mundo del Big Data. Sin embargo, configurar un entorno local…
Aprende Data Engineering con cursos prácticos en Udemy. Más de 10,800+ estudiantes ya están aprendiendo.
 Bestseller
Bestseller Bestseller
Bestseller



 Nuevo
Nuevo