 Python
Python UV: El Gestor de Python que viene a jubilar a pip, Poetry y pyenv
Si llevas tiempo desarrollando en Python, conoces bien «el ritual»: instalas una versión de Python con pyenv, creas un entorno virtual con venv, instalas paquetes…
Python Si llevas tiempo desarrollando en Python, conoces bien «el ritual»: instalas una versión de Python con pyenv, creas un entorno virtual con venv, instalas paquetes…
 Polars
Polars Polars puede ser hasta 100 veces más rápido que Pandas en operaciones complejas. En este artículo comparamos ambas bibliotecas en rendimiento, sintaxis y casos de…
 Apache Spark
Apache Spark Optimización de PySpark para el procesamiento de datos masivos En la era del big data, manejar volúmenes masivos de información es crucial para las empresas…
 Apache Spark
Apache Spark Trabajar con grandes volúmenes de datos requiere soluciones de almacenamiento robustas y escalables. AWS S3 (Simple Storage Service) es una de las opciones más utilizadas…
 Apache Spark
Apache Spark El almacenamiento en caché permite que Spark conserve los datos en todos los cálculos y operaciones. De hecho, esta es una de las técnicas más…
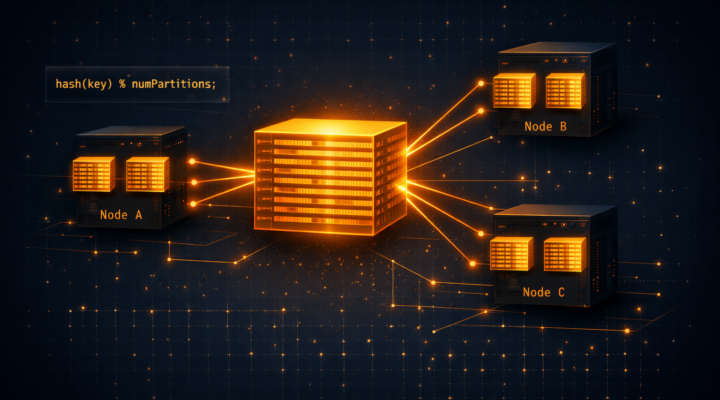 Apache Spark
Apache Spark Los RDD operan con datos no como una sola masa de datos, sino que administran y operan los datos en particiones repartidas por todo el…
 Apache Spark
Apache Spark Apache Spark es uno de los frameworks de procesamiento de datos más utilizados en el mundo del Big Data. Sin embargo, configurar un entorno local…