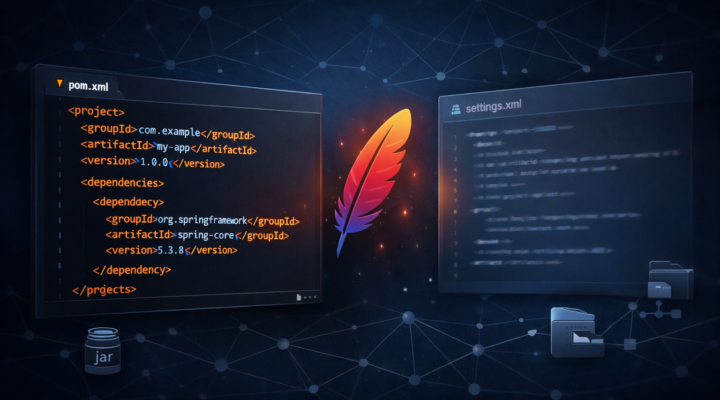
 Apache Maven
Apache Maven pom.xml y settings.xml en Maven: guía completa con ejemplos
En este artículo, examinaremos a fondo los archivos pom.xml y settings.xml en Apache Maven, incluyendo ejemplos prácticos y explicaciones detalladas de sus componentes. Si trabajas…