 Scala
Scala
Manejo de números en Scala
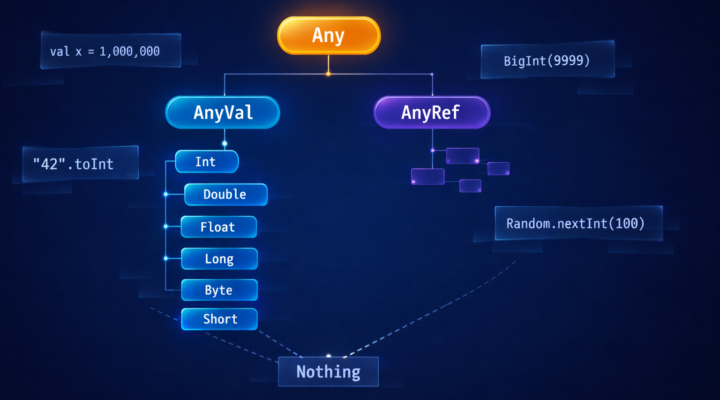
Introducción En este artículo vamos a aprender sobre el manejo de números en Scala. En Scala, los tipos Byte, Short, Int, Long y Char se…
Scala
Introducción En este artículo vamos a aprender sobre el manejo de números en Scala. En Scala, los tipos Byte, Short, Int, Long y Char se…
 Scala
Scala
Puede que esté acostumbrad@ a crear interfaces puras en otros lenguajes, declarando métodos sin implementaciones, y desea usar un trait como interfaz en Scala y…
 Scala
Scala
En cualquier lenguaje de programación, el manejo de excepciones es una parte fundamental para escribir código robusto. Scala ofrece un mecanismo de manejo de excepciones…
 Scala
Scala
A veces necesitamos encontrar patrones en strings en Scala. Un caso muy común sería, por ejemplo, verificar si un String contiene una expresión regular. Una…
 Apache Spark
Apache Spark
El almacenamiento en caché permite que Spark conserve los datos en todos los cálculos y operaciones. De hecho, esta es una de las técnicas más…
 Apache Spark
Apache Spark
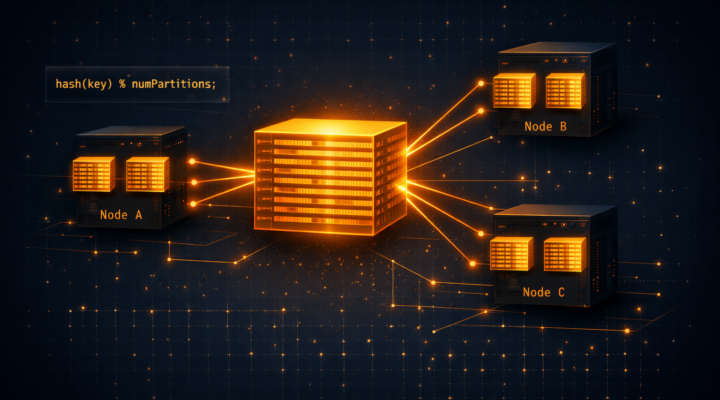
Los RDD operan con datos no como una sola masa de datos, sino que administran y operan los datos en particiones repartidas por todo el…
 Apache Maven
Apache Maven
Apache Maven está diseñado para crear compilaciones portátiles que se espera que funcionen en diferentes plataformas y en varios entornos de tiempo de ejecución. Puede…
 Apache Spark
Apache Spark
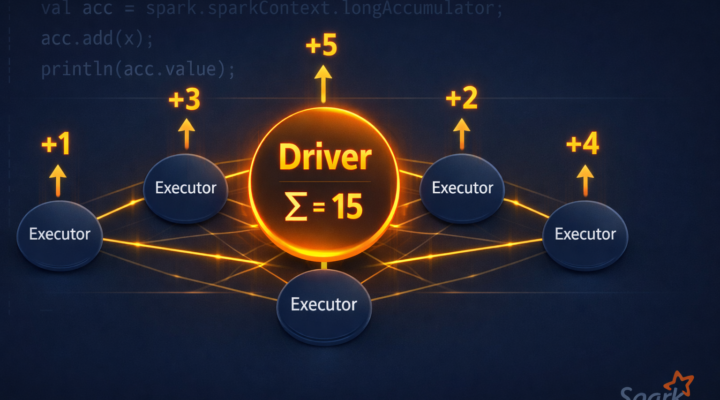
Los acumuladores son variables compartidas entre ejecutores que normalmente se utilizan para agregar contadores a su programa Spark. En un entorno distribuido como Apache Spark,…
 Apache Maven
Apache Maven
¿Qué es un JAR con dependencias? Un requisito típico de los proyectos es agregar la salida junto con sus dependencias, módulos y otros archivos en…