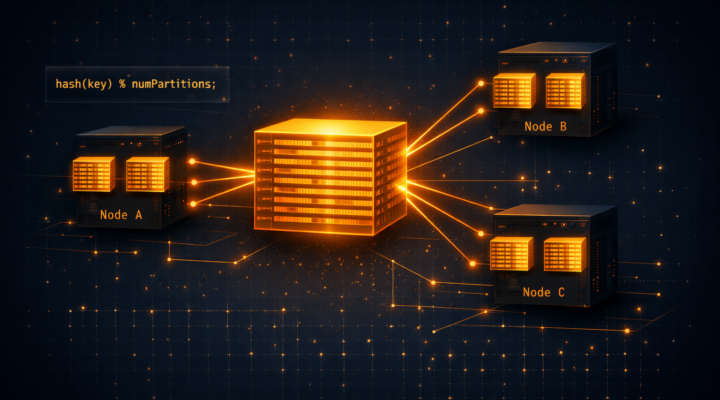
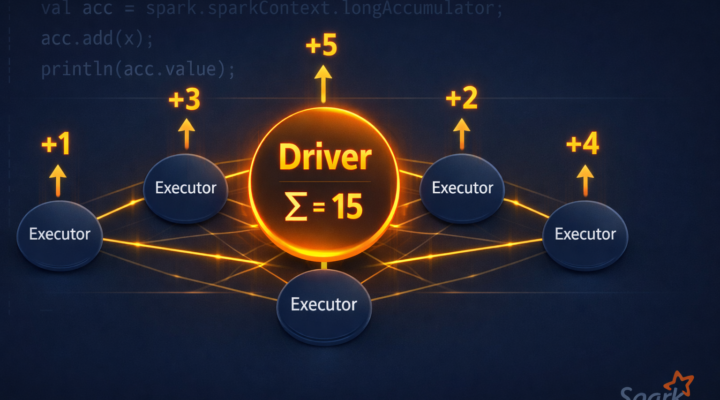
Apache Spark
Apache Spark
Arquitectura de Apache Spark: Una Guía Completa
Apache Spark se ha convertido en una herramienta fundamental en el ecosistema del Big Data, revolucionando la forma en que procesamos grandes volúmenes de información.…