 Apache Spark
Apache Spark Desmitificando el Optimizador Catalyst de Apache Spark
Desmitificando el Optimizador Catalyst de Apache Spark El procesamiento de grandes volúmenes de datos es una tarea crítica en el campo de la ingeniería de…
Apache Spark Desmitificando el Optimizador Catalyst de Apache Spark El procesamiento de grandes volúmenes de datos es una tarea crítica en el campo de la ingeniería de…
 Apache Spark
Apache Spark Optimización de PySpark para el procesamiento de datos masivos En la era del big data, manejar volúmenes masivos de información es crucial para las empresas…
 Apache Spark
Apache Spark RDDs y DataFrames en Spark SQL En Spark SQL, existen dos formas principales de trabajar con datos estructurados: RDDs y DataFrames. Mientras que los RDDs…
 Apache Spark
Apache Spark Diferentes formas de crear un RDD en PySpark Los RDD (Resilient Distributed Datasets) son la estructura de datos fundamental de Apache Spark. Aunque hoy en…
 Apache Spark
Apache Spark Trabajar con grandes volúmenes de datos requiere soluciones de almacenamiento robustas y escalables. AWS S3 (Simple Storage Service) es una de las opciones más utilizadas…
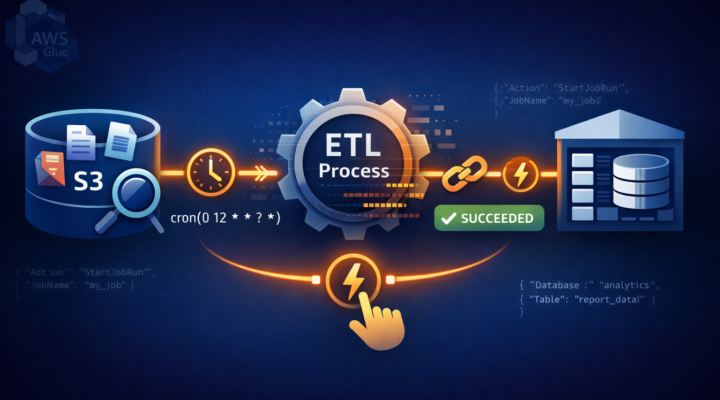 AWS Glue
AWS Glue En este artículo analizaremos los aspectos fundamentales que debemos conocer sobre los triggers en AWS Glue. ¿Qué son los triggers en AWS Glue? En AWS…
 AWS Glue
AWS Glue Introducción a Data Catalog y crawlers en AWS Glue En este artículo estaremos dando una introducción al Data Catalog de AWS Glue y a los…
 AWS Glue
AWS Glue En la era actual de datos masivos y análisis empresariales, la capacidad de gestionar y transformar datos de manera eficiente es esencial. AWS Glue es…
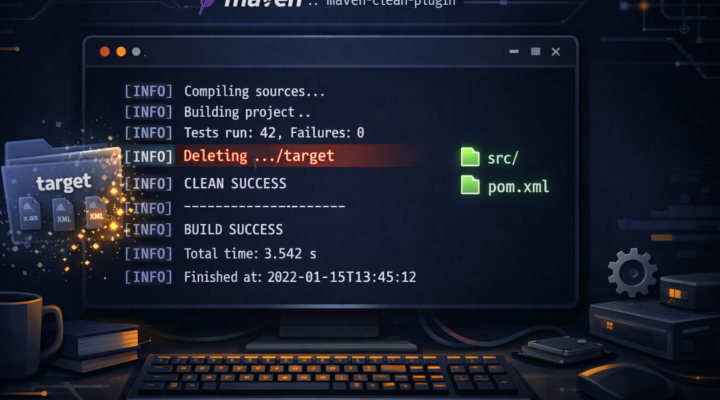 Apache Maven
Apache Maven Cuando trabajamos en Maven es muy habitual necesitar agregar y configurar complementos (plugins) al mismo para poder usarlos para realizar tareas de compilación necesarias. Maven…
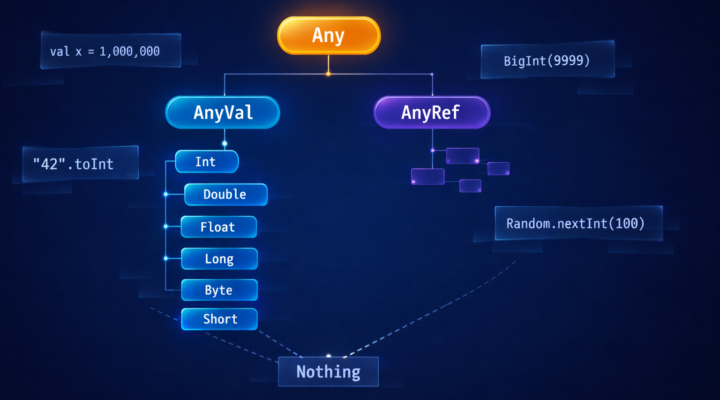 Scala
Scala Introducción En este artículo vamos a aprender sobre el manejo de números en Scala. En Scala, los tipos Byte, Short, Int, Long y Char se…