
 AWS Glue
AWS Glue
AWS Glue triggers
En este artículo analizaremos los aspectos fundamentales que debemos conocer sobre los triggers en AWS Glue. ¿Qué son los triggers en AWS Glue? En AWS…
En este artículo estaremos dando una introducción al Data Catalog de AWS Glue y a los crawlers. Además, mostraremos el flujo general de trabajo de cómo un crawler llena el Data Catalog de AWS Glue.
Antes de entrar en detalle sobre el Data Catalog y los crawlers, es importante entender qué es AWS Glue en términos generales. AWS Glue es un servicio de integración de datos completamente administrado (serverless) que facilita la preparación y carga de datos para su posterior análisis. Con AWS Glue podemos descubrir, preparar y combinar datos de forma sencilla para el análisis, el machine learning y el desarrollo de aplicaciones.
AWS Glue se compone de varios elementos clave:
Data Catalog.Dentro de este ecosistema, el Data Catalog y los crawlers son los componentes fundamentales para el descubrimiento y la catalogación de datos.
El Data Catalog de AWS Glue contiene referencias a datos que se utilizan como orígenes y destinos de nuestros jobs de extracción, transformación y carga en AWS Glue. Para crear nuestro data warehouse o data lake, debemos catalogar estos datos. AWS Glue Data Catalog es un índice que contiene la ubicación, el esquema y las métricas de tiempo de ejecución de nuestros datos. Podemos utilizar la información del Data Catalog para crear y supervisar nuestros jobs de ETL. La información en el Data Catalog se almacena en tablas de metadatos, donde cada tabla especifica un único data store. Por lo general, deberemos ejecutar un crawler para realizar un inventario de los datos en nuestros data stores, pero existen otras formas de agregar tablas de metadatos a nuestro Data Catalog.
Para entender mejor cómo se organiza la información dentro del Data Catalog, es importante conocer sus componentes principales:
Data Catalog. Una database no almacena datos reales, sino que agrupa las definiciones de tablas relacionadas. Por ejemplo, podríamos tener una database llamada ventas_db que contenga las tablas de metadatos correspondientes a todos nuestros archivos de ventas almacenados en S3.Data Catalog es una definición de metadatos que describe la estructura de nuestros datos en un data store. Una tabla incluye información como el nombre de las columnas, los tipos de datos, el formato del archivo (CSV, Parquet, JSON, etc.), la ubicación física de los datos y las propiedades de serialización/deserialización (SerDe).Data Catalog almacena también la información de las particiones, lo que permite a los servicios como Amazon Athena y Amazon Redshift Spectrum realizar consultas más eficientes al leer solo las particiones relevantes.Una de las grandes ventajas del Data Catalog es que funciona como un repositorio de metadatos centralizado compatible con múltiples servicios de AWS:
Data Catalog directamente para ejecutar consultas SQL sobre datos en S3 sin necesidad de configuración adicional.Data Catalog.Data Catalog como metastore de Apache Hive, reemplazando la necesidad de un metastore externo.Esta integración convierte al Data Catalog en una pieza central dentro de cualquier arquitectura de datos en AWS.
Un crawler es un programa que se conecta a un data store (origen o destino), avanza a través de una lista priorizada de clasificadores para determinar el esquema de los datos, y luego crea tablas de metadatos en el Data Catalog. Los crawlers pueden escanear diversos tipos de data stores, incluyendo:
El siguiente diagrama muestra cómo los crawlers de AWS Glue interactúan con los data stores y otros elementos para completar el Data Catalog.
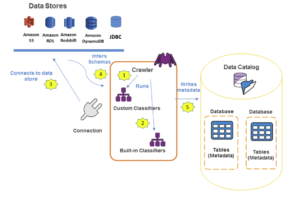
A continuación vamos a explicar el flujo general de trabajo de cómo un crawler llena el Data Catalog de AWS Glue.
En el primer paso, un crawler ejecuta cualquier clasificador personalizado que elijamos para inferir el formato y el esquema de nuestros datos. Nosotros podemos proporcionar el código para los clasificadores personalizados y estos se ejecutarán en el orden que especifiquemos. ¿Cómo funciona la jerarquía aquí? El primer clasificador personalizado que reconozca con éxito la estructura de nuestros datos se utiliza para crear un esquema y por tanto se omiten los clasificadores personalizados que se encuentran más abajo en la lista.
Si ningún clasificador personalizado coincide con el esquema de nuestros datos, los clasificadores integrados (representados en la imagen por built-in) intentan reconocer el esquema de nuestros datos. Un ejemplo de un clasificador integrado pudiera ser, por ejemplo, uno que reconoce un JSON.
AWS Glue incluye clasificadores integrados para los formatos más comunes:
| Formato | Descripción |
|---|---|
| CSV | Archivos de valores separados por comas |
| JSON | JavaScript Object Notation |
| Parquet | Formato columnar de Apache |
| Avro | Formato de serialización de Apache |
| ORC | Optimized Row Columnar |
| XML | Extensible Markup Language |
El crawler se conecta al data store. Aquí debemos tener en cuenta que algunos data stores requieren propiedades de conexión para el acceso del crawler. Las connections en AWS Glue almacenan credenciales, URI del host, número de puerto y otras propiedades necesarias para conectarse a data stores que no son nativos de AWS (como bases de datos JDBC) o que se encuentran dentro de una VPC.
En el siguiente paso, el esquema inferido se crea para nuestros datos. El crawler analiza una muestra de los datos para determinar la estructura: nombres de columnas, tipos de datos, delimitadores y otras propiedades del formato.
Y por último, el crawler escribe los metadatos en el Data Catalog. La definición de una tabla en el Data Catalog contiene metadatos sobre los datos en nuestro data store. La tabla se escribe en una database, que no es más que un contenedor de tablas en el Data Catalog. Los atributos de una tabla incluyen la clasificación, que es una etiqueta creada por el clasificador que infirió el esquema de la tabla.
Para sacar el máximo provecho de los crawlers en AWS Glue, es recomendable tener en cuenta las siguientes prácticas:
crawler para que se ejecute periódicamente y mantenga el Data Catalog actualizado.crawler a un bucket completo, es mejor apuntarlo a prefijos específicos para reducir el tiempo de ejecución y evitar catalogar datos innecesarios.crawler a inferir esquemas de forma más precisa.crawler los clasifique incorrectamente.crawler ante cambios de esquema (añadir columnas, eliminar columnas, etc.) para evitar modificaciones inesperadas en el Data Catalog.El Data Catalog y los crawlers son componentes esenciales de AWS Glue que simplifican enormemente el proceso de descubrimiento y catalogación de datos. El Data Catalog actúa como un repositorio centralizado de metadatos que se integra con múltiples servicios de AWS, mientras que los crawlers automatizan la tarea de escanear data stores, inferir esquemas y registrar toda esa información en el catálogo.
Comprender este flujo de trabajo — desde la ejecución de clasificadores hasta la escritura de metadatos — es fundamental para diseñar pipelines de datos eficientes y bien organizados en AWS.
AWS Glue
En este artículo analizaremos los aspectos fundamentales que debemos conocer sobre los triggers en AWS Glue. ¿Qué son los triggers en AWS Glue? En AWS…
 AWS Glue
AWS Glue
En la era actual de datos masivos y análisis empresariales, la capacidad de gestionar y transformar datos de manera eficiente es esencial. AWS Glue es…